Design and implementation of a soil-sediment database system for complex geoscientific and spatial data
Due to advances in experimental technologies, sensor technology and computer based methods, ever more extensive and complex data sets are being generated in the geosciences, which in turn originate from an increasing number of sources and methods. In order to meet the increasing demands on research data management, the project “Design and Implementation of a Soil-Sediment Database System for Complex Geoscientific and Spatial Data” investigated the specific needs and requirements for a research data management system that can effectively manage complex geomorphological and geochronological datasets. In order to implement such a system, a detailed requirements analysis based on various components was first carried out. In addition to participative observations and semi-structured expert interviews, during which direct insights into the work processes in the laboratory and in the field were gained, the analysis of existing data sets also played a central role. Documentation, raw data as well as processed data from different studies and working groups were systematically examined in order to understand the structure, scope and complexity of different research datasets. This analysis was crucial to determine which data types and formats need to be integrated into the system, which processes are required to process and link the data and how efficient data storage and retrieval can be implemented.
In the next step, a suitable data model was developed to efficiently organize the complex geomorphological and geochronological data sets so that a precise mapping of the different data types, their links and spatial positioning is possible.
Finally, the database system was implemented, in which the system architecture and the data model were realized using the Python framework Django and a PostgreSQL database (PostGIS). Particular attention was paid to the usability of the system in order to minimize the entry threshold for new users.
This structured approach enabled the digitization of parts of the research data management, which meets the increasing requirements in the geosciences. Nevertheless, the system requires continuous further development in order to adapt to the constantly changing requirements in research.
Written and developed by M.Sc. Dennis Handy.
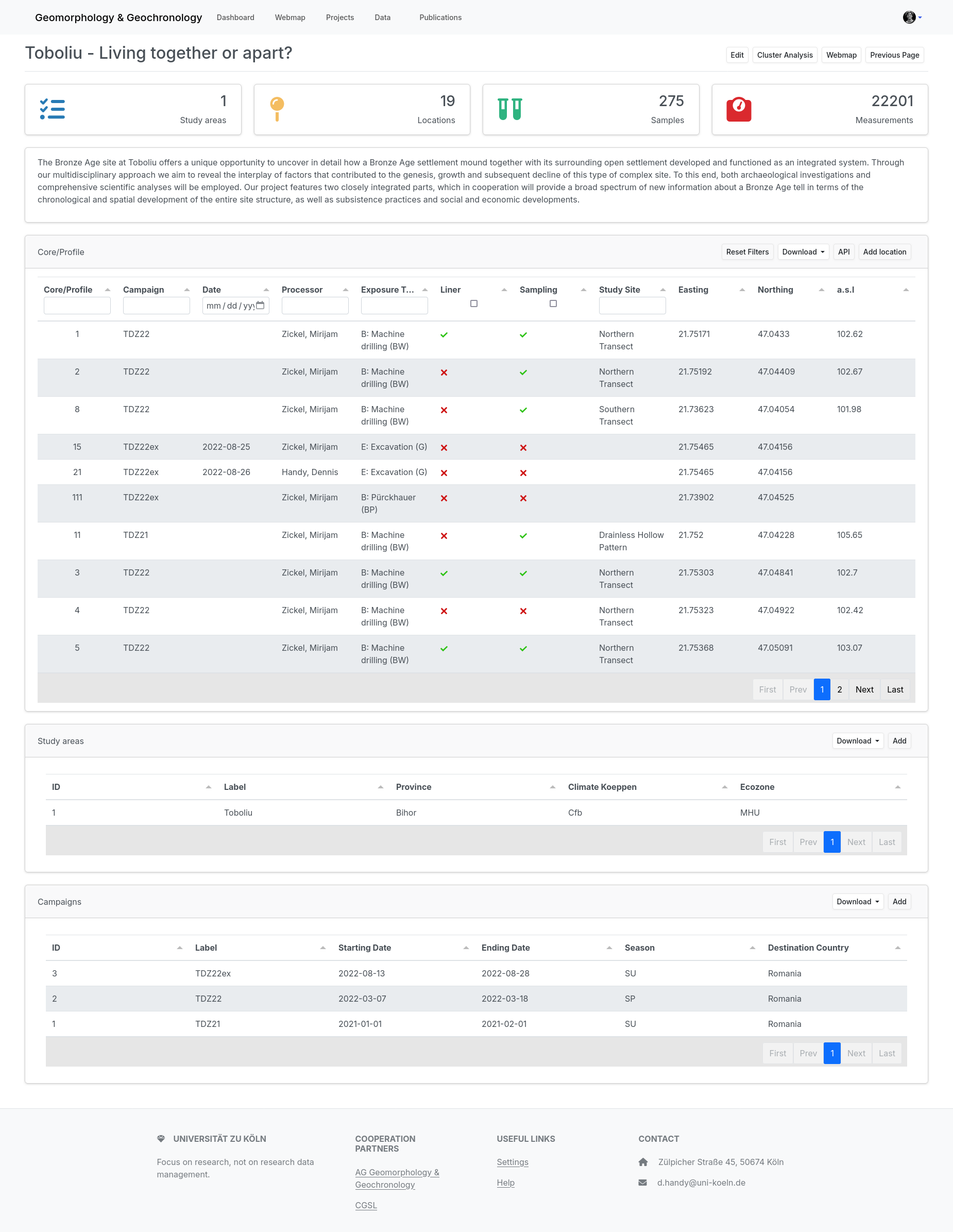
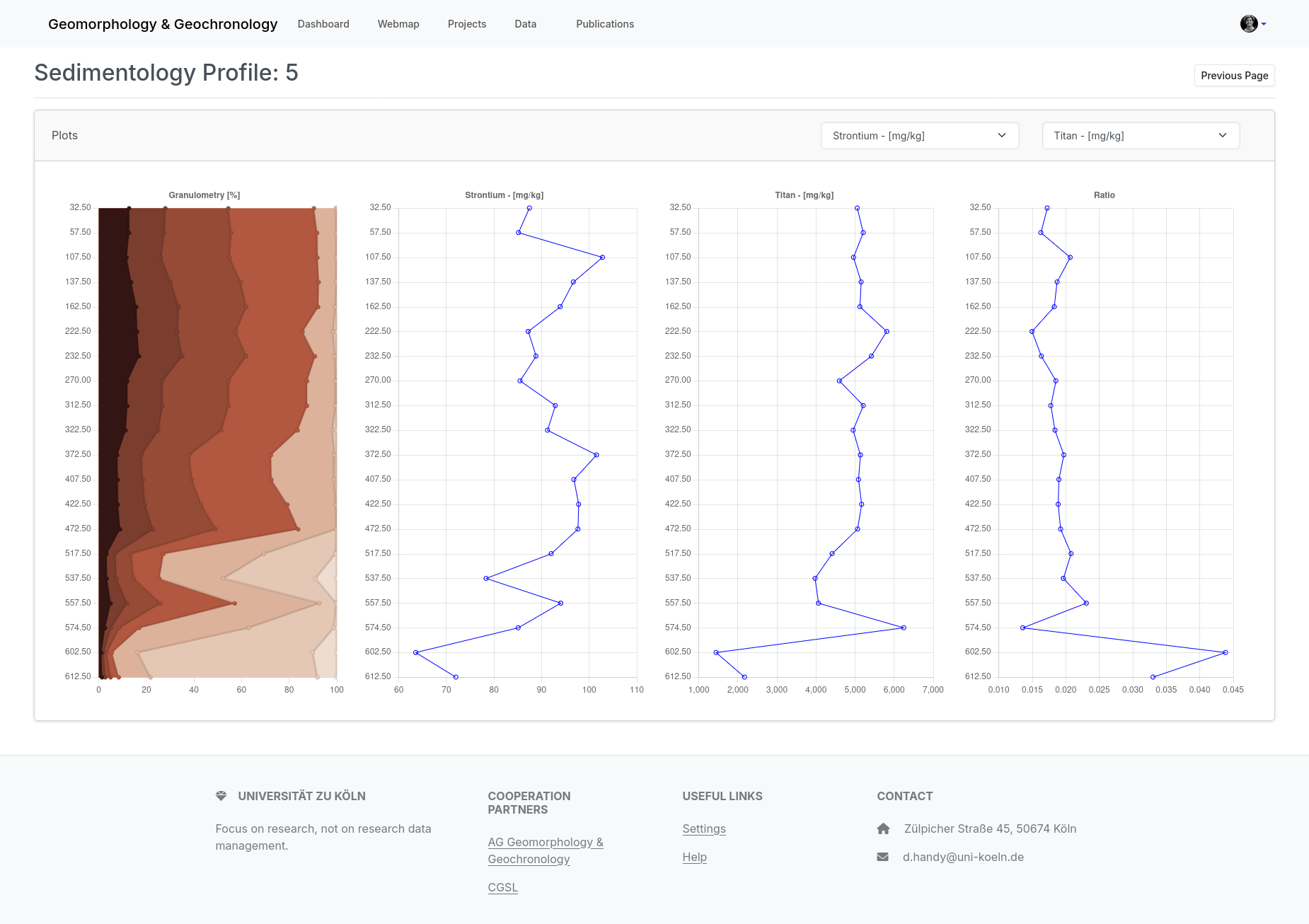
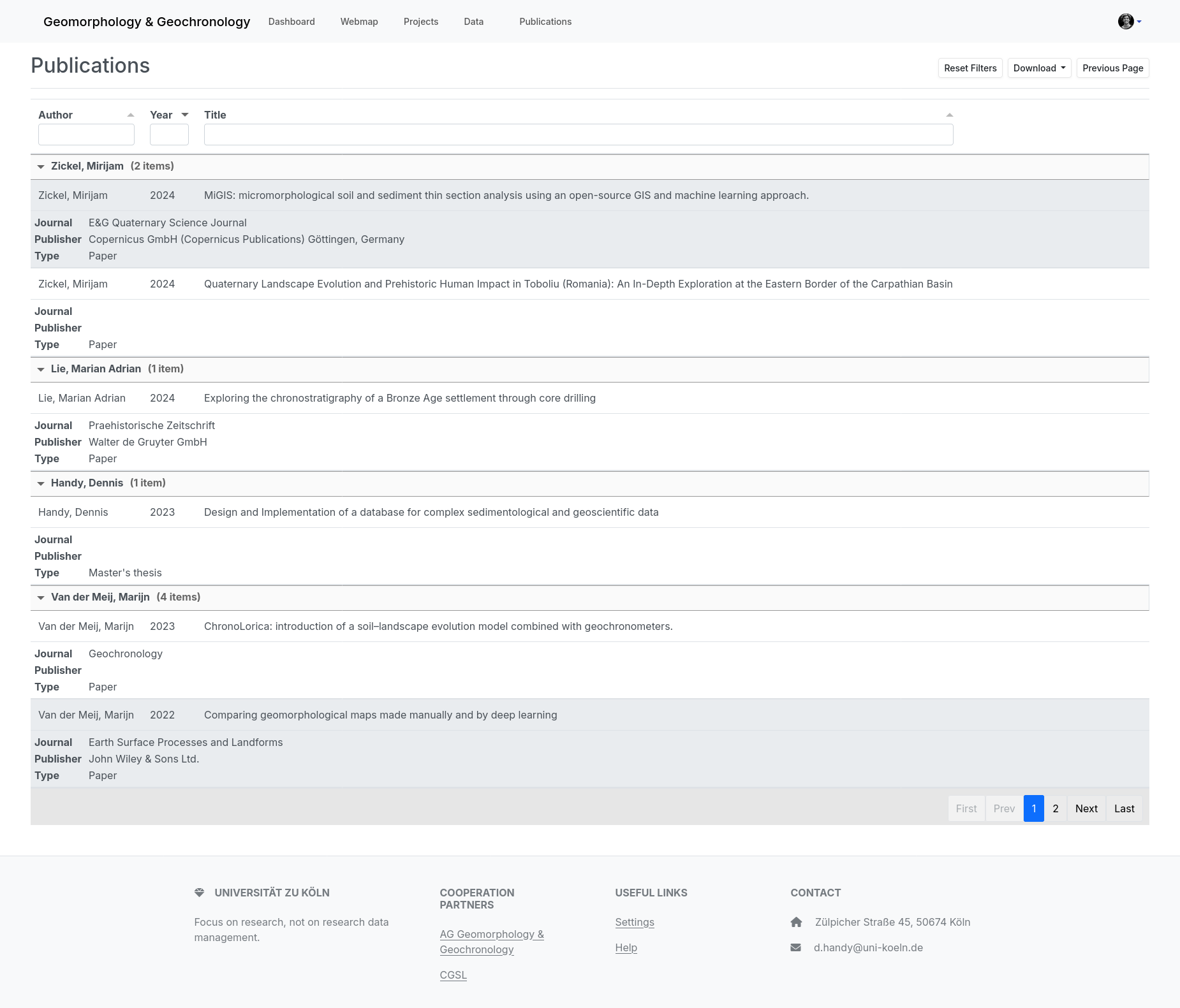

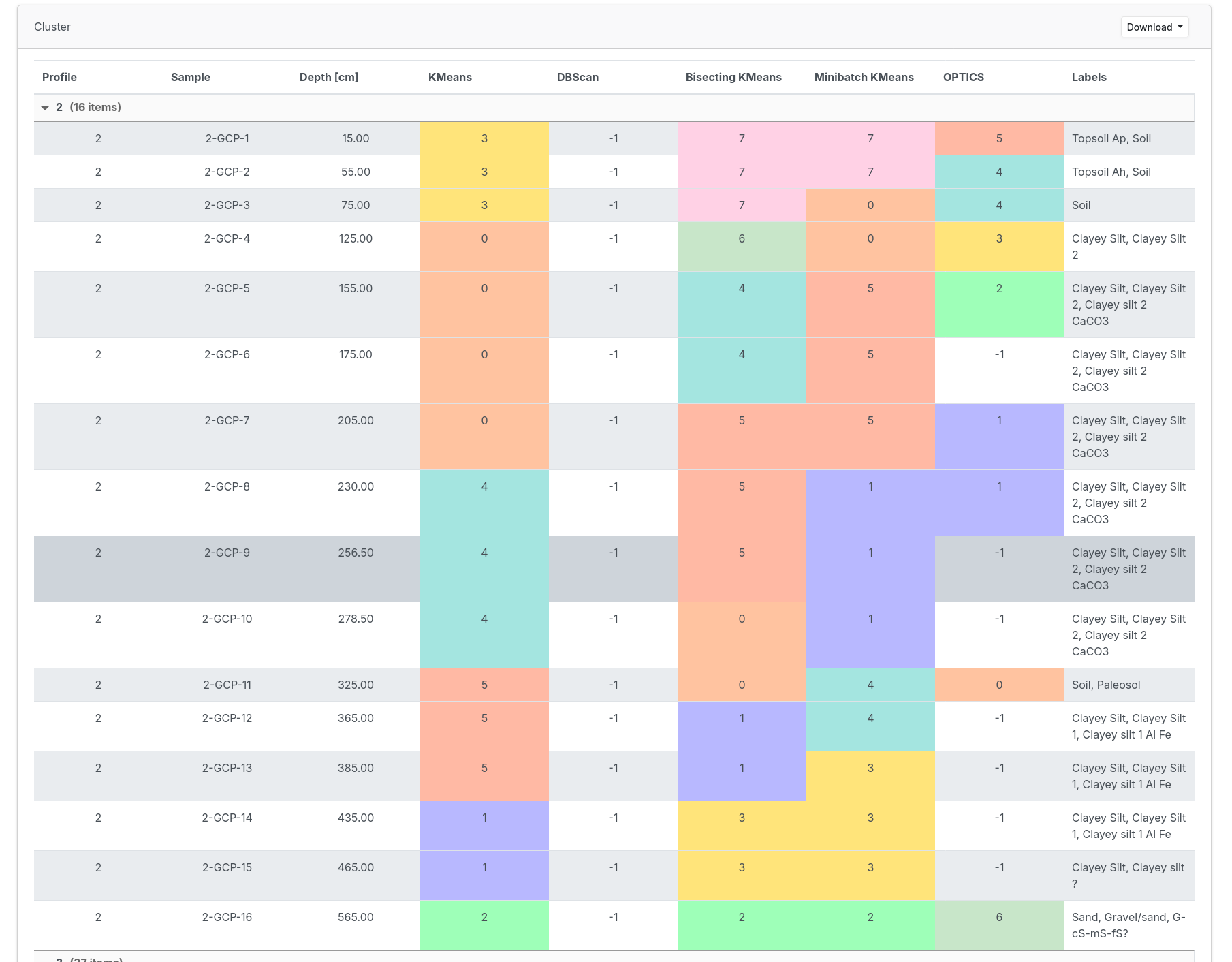
The images show various screenshots from use with the database.
1) The input of measurement data is designed to be user-friendly. The possible data types are those requested by the surveyed and participating working groups, and the list can be extended in principle. With the help of a filterable display, the lists of profiles, campaigns and measurements in general remain clearly arranged.
2) In addition to displaying the database tables, selected data and calculated data can also be displayed. Using a sediment profile, the grain size, the proportion of strontium and titanium and the ratio of both elements are presented graphically. The user has only entered the measured values of strontium and titanium in mg/kg in the database. The calculation of the grain sizes and the ratio as well as the plotting is executed within the database system.
3) Publications can be managed within the database system, i.e. entered, filtered, searched and displayed.
4) The web interface includes a basic WebGIS to visualize the field documentation and measurements directly in their spatial context.
5) The database supports users in exploratory data analysis by making connections in the data sets visible, for example through clustering algorithms based on the measurement data.